


Search engines” such as google are huge indexes- use “crawlers” or “spiders” to search for content
Crawlers
Crawlers discover content through various means. one being by pure discovery, where a url is visited by the crawlers and information regarding the content type of the website is returned to the search engine let’s visualize some things once a web crawler discovers a domain such as mywebsite.com, it will index the entire contents of the domain, looking for keywords and other information
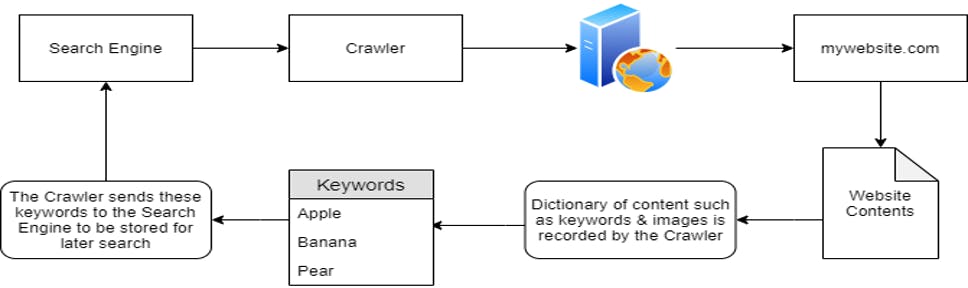
Search Engine Optimization (SEO)
how your domain will be prioritized by search engines. there are many factors • how responsive your website is to the different browser types? • how easy it is to crawl your website through the use of “sitemaps” • what kind of keywords your website has? NB: there is a lot of complexity in how the various search engines individually “point-score” or rank these domains including vast algorithms there are various online tools that will show you just how optimized your domain is
ROBOTs.txt
There are a few cases where we wouldn’t want all of the contents of our website to be indexed, e.g., a secret administrator login page? This robots.txt file is the first thing indexed by “crawlers” when visiting a website. This file must be served at the root directory – specified by the webserver itself. It defines the permissions the “crawlers” has to the website. Robot.txt specify what files and directories that we do or don’t want to be indexed by the crawler
A very basic markup of a Robots.txt is like the following
> 1. User-agent : *
> 2. Allow: /
> 3. Sitemap: http://mywebsite.com/sitemap.xml
Here we have a few keywords
Keyword & Function
User-agent: Specify the type of “crawler” that can index your site (the asterisk being a wildcard, allowing all “user agents”)
Allow: Specify the directories or file(s) that the “crawler” can index
Disallow: Specify the directories or file(s) that the “crawler” cannot index
Sitemap: Location of the sitemap
NB: say we want to hide directories or files from a “crawler”;
> 1. User-agent: *
> 2. Disallow: /super-secret-directory/
> 3. Disallow: /not-a-secret/but-this-is/
> 4. Sitemap: http://mywebsite.com/sitemap.xml
NB: what if we only wanted certain “crawlers” to index or site;
> 1. User-agent: Googlebot
> 2. Allow: /
> 3. User-agent: msnbot
> 4. Disallow: /
NB: how about preventing files from being indexed;
> 1. User-agent: *
> 2. Disallow: /* .ini$
> 3. Sitemap: http://mywebsite .com/sitemap.xml
SITEMAPS
Comparable to geographical maps in real life. They specify the necessary routes to find content on the domain.
Using Google for advanced searching
• Using quotation marks: Google will interpret everything in between these quotation marks as exact and only return the results of the exact phrase provided.
"bbc.co.uk"
• Refining our queries: to search a specified site for a keyword we use the site. e.g.
site: bbc.co.uk Ghana news
• Use the Keyword “...” to search within a time frame. For example, say you wanted to find an article about developers or anything to do with developers between 1992 and 1999, this is what it would look like:
Developer 1992...1999
• Use the Keyword - to exclude a word. If I wanted to know more about Android development but didn't want to include flutter related skills in my search results, I would search it like this:
android development -flutter
• Use the keyword to replace missing words. Trying to search for something but you happen to have forgotten some words? Don't worry, try using the to replace the missing word that you have forgotten. Like this:
*oriented programming in python
• If you're looking for a definition of a word, use the keyword define: to find a definition. If I wanted to find the definition of object-oriented programming, this would give results of all articles with definitions of object-oriented programming. This is how I would do it: define:
object-oriented programming
Few common terms we can use
Term & Action
Filetype: Search for a file by it extension
Intitle: The specified phrase must appear in the title of the page